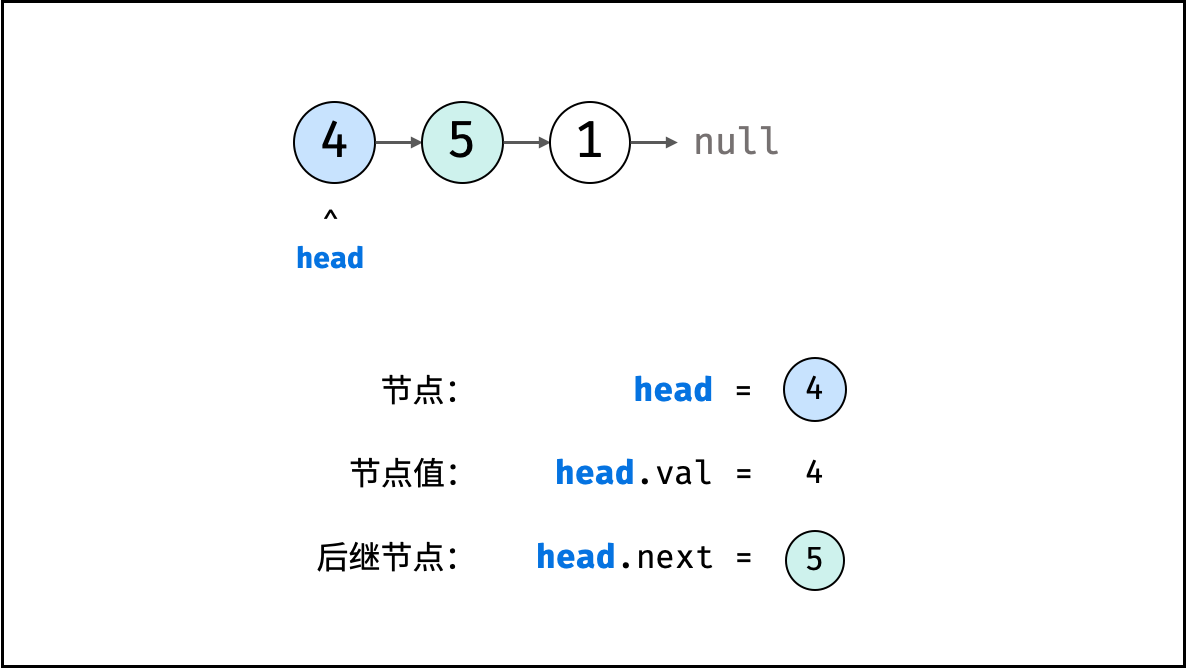
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None classSolution: defdeleteNode(self, head: ListNode, val: int) -> ListNode: if head.val == val: #链表头节点需要删除, return head.next lian = head while lian and lian.next: if lian.next.val == val: lian.next = lian.next.next lian = lian.next return head
训练计划 III
给定一个头节点为 head 的单链表用于记录一系列核心肌群训练编号,请将该系列训练编号 倒序 记录于链表并返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: deftrainningPlan(self, head: Optional[ListNode]) -> Optional[ListNode]: #双指针 cur, pre = head, None#定义头节点和空节点 while cur: tmp = cur.next#暂存cur的下一个节点 cur.next = pre #cur指向pre pre = cur #将pre取为cur原节点 cur = tmp #将cur取为tmp节点,即为原cur的下一个节点 return pre #pre就是反向链表
训练计划 II
给定一个头节点为 head 的链表用于记录一系列核心肌群训练项目编号,请查找并返回倒数第 cnt 个训练项目编号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: deftrainingPlan(self, head: Optional[ListNode], cnt: int) -> Optional[ListNode]: cur = head #单指针 i = 1 while cur.next: #指针遍历链表,查看有多少个节点 cur = cur.next i += 1 cur = head #指针回到头节点 j = 1 while j != i+1-cnt: #指针遍历到目标节点,输出节点 cur = cur.next j += 1 return cur
1 2 3 4 5 6 7 8 9
#双指针,两指针的间隔为cnt classSolution: deftrainingPlan(self, head: ListNode, cnt: int) -> ListNode: former, latter = head, head for _ inrange(cnt): former = former.next while former: former, latter = former.next, latter.next return latter
classSolution: deffileCombination(self, target: int) -> List[List[int]]: lst=[] max = target // 2 for n inrange(max,1,-1): #因为需要升序排列,所以n从大到小遍历 m = target/n - (n-1)/2#通过数学求和公式,求出m的值 if m == int(m) and m>0: #如果m为整数,符合要求 lst.append(list(range(int(m),int(m+n)))) return lst
按规则计算统计结果
为了深入了解这些生物群体的生态特征,你们进行了大量的实地观察和数据采集。数组 arrayA 记录了各个生物群体数量数据,其中 arrayA[i] 表示第 i 个生物群体的数量。请返回一个数组 arrayB,该数组为基于数组 arrayA 中的数据计算得出的结果,其中 arrayB[i] 表示将第 i 个生物群体的数量从总体中排除后的其他数量的乘积。
#累乘再除法 class Solution: def statisticalResult(self, arrayA: List[int]) -> List[int]: total = 1 arrayB = [] n = len(arrayA) j = 0 for i in range(n): if arrayA[i] == 0: m = i #记录下0的位置,当只有一个0的时候,避免循环 j += 1 continue #跳过0,算出其它位置的total total *= arrayA[i] if j>1: #两个及以上0时,全部输出0 arrayB = [0]*n elif j == 1: #一个零时,零的位置输出total,其它位置输出0 arrayB = [0]*n arrayB[m] = total else: for i in range(n): arrayB.append(int(total/arrayA[i])) return arrayB
#按矩阵外围一圈来循环 classSolution: defspiralArray(self, array: List[List[int]]) -> List[int]: ifnot array: return [] #矩阵为空 m = len(array) #行 n = len(array[0]) #列 defmatrix(i): #定义矩阵函数,输出m-2i * n-2i的矩阵 lst = [] for j inrange(i,m-i): lst.append(array[j][i:n-i]) return lst defbianli(lst): #定义遍历函数,m-2i * n-2i的矩阵的外围一圈遍历 m1 = len(lst) #局部矩阵的行 n1 = len(lst[0]) #局部矩阵的列 lst2 = [] if m1 == 1: #局部矩阵的行为1,即为行向量时 return lst[0] if n1 == 1: #局部矩阵的行为1,即为列向量时 for j inrange(m1): lst2 += lst[j] return lst2 lst2 = lst[0] #局部矩阵的行、列都大于1,即为矩阵时 for j inrange(1,m1-1): lst2.append(lst[j][-1]) lst2 += lst[-1][-1:-n1-1:-1] for j inrange(m1-2,0,-1): lst2.append(lst[j][0]) return lst2 output = [] k = min(m,n) #用行列数中的较小者判断遍历应该循环L次 l = (k+1)//2if k % 2else k//2 for i inrange(0,l): output += bianli(matrix(i)) return output
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#按四条边界来循环 classSolution: defspiralArray(self, array: List[List[int]]) -> List[int]: ifnot array: return [] l, r, t, b, res = 0, len(array[0]) - 1, 0, len(array) - 1, [] whileTrue: for i inrange(l, r + 1): res.append(array[t][i]) # left to right t += 1 if t > b: break for i inrange(t, b + 1): res.append(array[i][r]) # top to bottom r -= 1 if l > r: break for i inrange(r, l - 1, -1): res.append(array[b][i]) # right to left b -= 1 if t > b: break for i inrange(b, t - 1, -1): res.append(array[i][l]) # bottom to top l += 1 if l > r: break return res
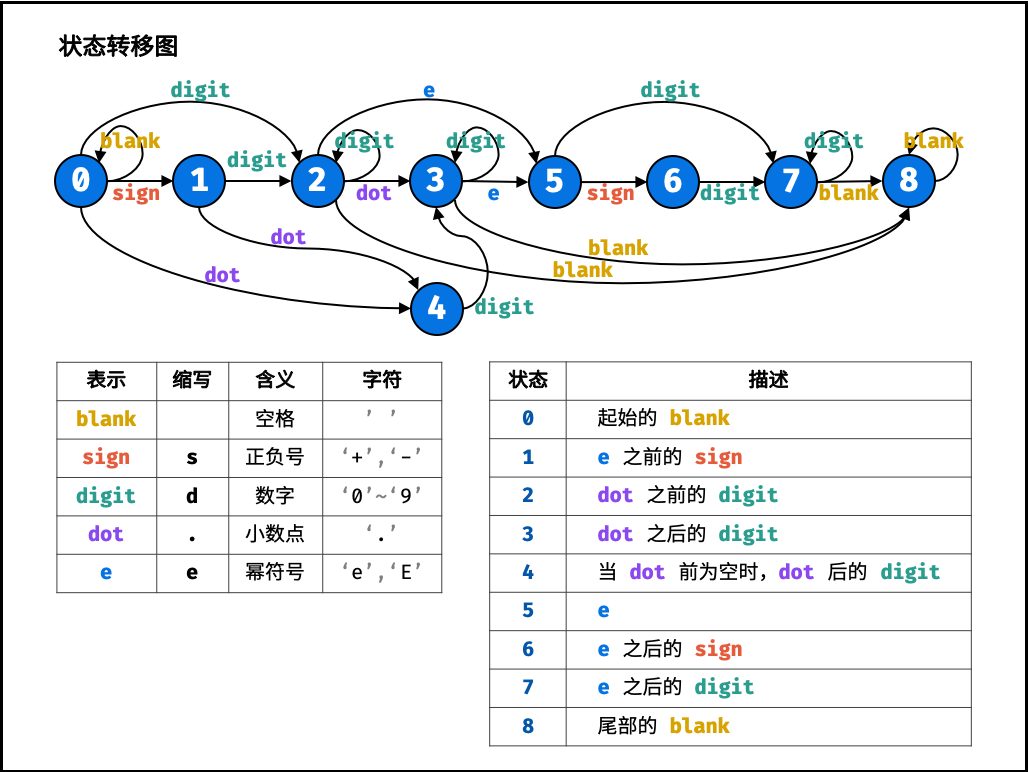
classSolution: defvalidNumber(self, s: str) -> bool: s = s.strip() n = len(s) ifnot s: returnFalse if n == 1andnot s[0].isdigit(): returnFalse#如果只有一位,必为数字,方便后续遍历 sign, index, point = 0, 0, 0 for i inrange(n): if s[i].isdigit(): continue ifnot s[i] in'+-eE.': returnFalse if s[i] in'+-': #+-不能出现在字符串最后一位,+-后一位必须是数字或者.,+-前一位不能是数字 ifnot (i+1-n and (s[i+1].isdigit() or s[i+1] == '.')) or (i and s[i-1].isdigit()): returnFalse #如果前面已经出现了+-或.,再出现+-号时前面一位必须为e/E elif (sign or point) and s[i-1] notin'eE': returnFalse else: sign = 1 continue if s[i] in'eE': #一个字符串中最多一个e或E,e不能出现在首位,eE不能出现在字符串最后一位,eE后一位必须是数字或+- if index or i == 0ornot (i+1-n and (s[i+1].isdigit() or s[i+1] in'+-')): returnFalse else: index = 1 continue else: #如果s[i]为'.' if index or point: returnFalse#一个字符串中最多一个. .不能写在eE的后面 elifnot (i or s[i+1].isdigit()): returnFalse#.在首位时,后一位为数字 elifnot (i+1-n or s[i-1].isdigit()): returnFalse#在末尾时,前一位为数字 elifnot (s[i-1].isdigit() or s[i+1].isdigit()): returnFalse#点在中间时,前后至少有一个为数字 else: point =1 continue returnTrue
classSolution: defvalidateStackSequences(self, pushed: List[int], popped: List[int]) -> bool: dict = {} for i inrange(len(pushed)): dict[pushed[i]] = i i = 0 while i < len(pushed): index = dict[popped[i]] #查看后面的元素是否乱序 for item in popped[i+1:]: ifdict[item] < dict[popped[i]]: ifdict[item] < index: index = dict[item] else: returnFalse i += 1 returnTrue
1 2 3 4 5 6 7 8 9
classSolution: defvalidateBookSequences(self, putIn: List[int], takeOut: List[int]) -> bool: stack, i = [], 0 for num in putIn: stack.append(num) # num 入栈 while stack and stack[-1] == takeOut[i]: # 循环判断与出栈 stack.pop() i += 1 returnnot stack
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right classSolution: defdecorateRecord(self, root: Optional[TreeNode]) -> List[int]: #BFS算法,广度优先 ifnot root: return [] queqe = collections.deque([root]) res = [] while queqe: tmp = queqe.popleft() res.append(tmp.val) #如果节点左右树不为空,则将左右树按顺序放进队列中 if tmp.left: queqe.append(tmp.left) if tmp.right: queqe.append(tmp.right) return res
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right classSolution: deflevelOrder(self, root: Optional[TreeNode]) -> List[List[int]]: #BFS算法,并通过1和flag判断该层是否遍历完 ifnot root: return [] queqe = collections.deque([1,root]) res = [] flag = False#判断是否为新的一层 tmp = [] while queqe: if queqe[0] == 1andnot flag: #遇1标志该一层结束 if tmp: res.append(tmp) #将该层数据tmp加到res中 queqe.popleft() tmp = [] #将tmp清空 flag = True continue node = queqe.popleft() tmp.append(node.val) if (node.left or node.right) and flag: queqe.append(1) flag = False if node.left: queqe.append(node.left) if node.right: queqe.append(node.right) ifnot queqe: res.append(tmp) #队列为空说明循环即将结束,将最后一层数据tmp加到res中 return res
#层级遍历 BFS classSolution: defcalculateDepth(self, root: TreeNode) -> int: ifnot root: return0 queue, res = [root], 0 while queue: #因为我们不需要真的遍历queue,即我们不需要queue的值,所以用tmp刷新队列即可 tmp = [] for node in queue: if node.left: tmp.append(node.left) if node.right: tmp.append(node.right) queue = tmp res += 1 return res
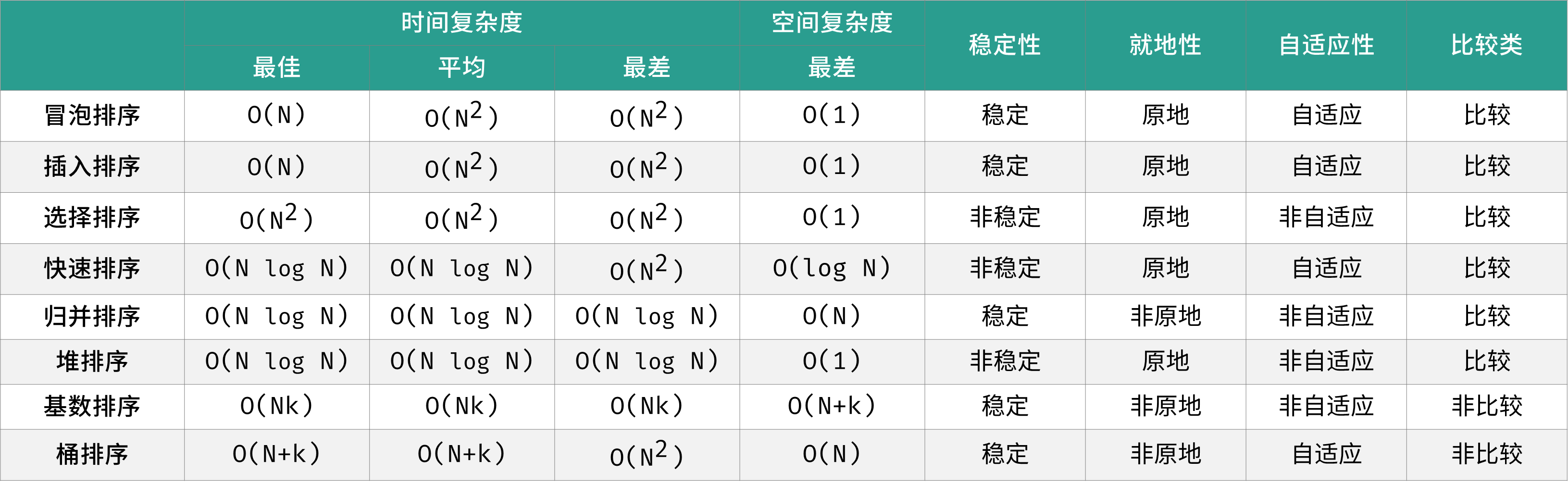
defquick_sort(nums, l, r): # 子数组长度为 1 时终止递归 if l >= r: return # 哨兵划分操作 i = partition(nums, l, r) # 递归左(右)子数组执行哨兵划分 quick_sort(nums, l, i - 1) quick_sort(nums, i + 1, r) defpartition(nums, l, r): # 以 nums[l] 作为基准数 i, j = l, r while i < j: while i < j and nums[j] >= nums[l]: j -= 1 while i < j and nums[i] <= nums[l]: i += 1 nums[i], nums[j] = nums[j], nums[i] nums[l], nums[i] = nums[i], nums[l] return i
defquick_sort(nums, l, r): # 子数组长度为 1 时终止递归 while l < r: #迭代代替递归 # 哨兵划分操作 i = partition(nums, l, r) # 仅递归至较短子数组,控制递归深度 if i - l < r - i: quick_sort(nums, l, i - 1) l = i + 1 else: quick_sort(nums, i + 1, r) r = i - 1
随机基准数
1 2 3 4 5 6 7 8 9 10 11 12
defpartition(nums, l, r): # 在闭区间 [l, r] 随机选取任意索引,并与 nums[l] 交换 ra = random.randrange(l, r + 1) nums[l], nums[ra] = nums[ra], nums[l] # 以 nums[l] 作为基准数 i, j = l, r while i < j: while i < j and nums[j] >= nums[l]: j -= 1 while i < j and nums[i] <= nums[l]: i += 1 nums[i], nums[j] = nums[j], nums[i] nums[l], nums[i] = nums[i], nums[l] return i
#哈希表 classSolution: defdismantlingAction(self, arr: str) -> str: hmap = collections.OrderedDict() for c in arr: hmap[c] = not c in hmap for k, v in hmap.items(): if v: return k return' '
#二分法 bisect函数 classSolution: defcountTarget(self, scores: List[int], target: int) -> int: a = bisect_left(scores,target) b = bisect_right(scores,target) return b-a
1 2 3 4 5 6 7 8 9 10 11
#直接二分法 classSolution: defcountTarget(self, scores: List[int], target: int) -> int: defhelper(tar): i, j = 0, len(scores) - 1 while i <= j: m = (i + j) // 2 if scores[m] <= tar: i = m + 1 else: j = m - 1 return i return helper(target) - helper(target - 1)
点名
某班级 n 位同学的学号为 0 ~ n-1。点名结果记录于升序数组 records。假定仅有一位同学缺席,请返回他的学号。
1 2 3 4 5 6 7 8
classSolution: deftakeAttendance(self, records: List[int]) -> int: i, j = 0, len(records) - 1 while i <= j: m = (i + j) // 2 if records[m] == m: i = m + 1 else: j = m-1 return i
dic = {} for i inrange(len(inorder)): dic[inorder[i]] = i #哈希表映射,将值映射为对应索引 return recur(0, 0, len(inorder)-1)
验证二叉搜索树的后序遍历序列
请实现一个函数来判断整数数组 postorder 是否为二叉搜索树的后序遍历结果。
1 2 3 4 5 6 7 8 9 10 11
classSolution: defverifyTreeOrder(self, postorder: List[int]) -> bool: defrecur(i,j): if i >= j :returnTrue#说明只有一个节点,即为叶节点,无需判断 p = i while postorder[p] < postorder[j]: p += 1#遍历小于根节点的值,即为左子树 m = p #m用来确定右子树范围 while postorder[p] > postorder[j]: p += 1#遍历大于根节点的值,即为右子树 #检验j根点的树是否符合预期(p=j),检验左子树和右子树是否为搜索树 return p == j and recur(i,m-1) and recur(m,j-1) return recur(0,len(postorder)-1)
classSolution: defmyPow(self, x: float, n: int) -> float: if x == 0: return0 if n < 0: x, n = 1/x, -n #转化为正幂讨论 res = 1 while n: if n & 1: res *= x #如果n二进制位为1,乘上x x *= x #x=x^2 n >>= 1#n右移一位 return res
#归并排序,考虑倒数对 classSolution: defreversePairs(self, record: List[int]) -> int: defmergesort(l,r): if l >= r: return0#长度为1,返回0 m = (l + r) // 2 res = mergesort(l, m) + mergesort(m+1, r) i ,j = 0, m - l + 1 tmp = record[l:r+1] for k inrange(l, r+1): if i == m - l + 1: #左子数组已经遍历完 record[k] = tmp[j] j += 1 elif j == r - l + 1or tmp[i] <= tmp[j]:#右子数组遍历完或左边数字小 record[k] = tmp[i] i += 1 else: #左边数字大,即为倒数对 record[k] = tmp[j] j += 1 res += m-l - i + 1#左子树组中i右边的数都比i大,都为倒数对 return res return mergesort(0, len(record)-1)
classSolution: deffib(self, n: int) -> int: if n <= 1: return n a, b = 0, 1 for _ inrange(n-1): #在计算的时候就取余,避免数值过大 a, b = b, (a+b) % int(1e9+7) return b
跳跃训练
今天的有氧运动训练内容是在一个长条形的平台上跳跃。平台有 num 个小格子,每次可以选择跳 一个格子 或者 两个格子。请返回在训练过程中,学员们共有多少种不同的跳跃方式。
classSolution: defcrackNumber(self, ciphertext: int) -> int: s = str(ciphertext) a, b = 1, 1 y = ciphertext % 10 while ciphertext > 9: #用进制考虑,额外空间复杂度为O(1) ciphertext //= 10 x = ciphertext % 10 c, a = a, b if10 <= 10*x+y <= 25: b += c y = x return b
1 2 3 4 5 6 7 8
classSolution: defcrackNumber(self, ciphertext: int) -> int: s = str(ciphertext) #额外空间复杂度为O(n) a, b = 1, 1 for i inrange(1,len(s)): c, a = a, b if10<= int(s[i-1:i+1]) <= 25: b = c + b return b
招式拆解 I
某套连招动作记作序列 arr,其中 arr[i] 为第 i 个招式的名字。请返回 arr 中最多可以出连续不重复的多少个招式。
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deflengthOfLongestSubstring(self, s: str) -> int: #动态规划 ifnot s: return0 dp, res = '', 0 for item in s: if item notin dp: dp += item else: if dp[-1] == item: dp = item else: dp = dp[dp.find(item)+1:] + item res = max(res, len(dp)) return res
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: deflengthOfLongestSubstring(self, s: str) -> int: #双指针,滑动窗口 ifnot s: return0 res, dic = 1, {} i, j = -1, 0 while j < len(s): if s[j] in dic: i = max(i,dic[s[j]]) dic[s[j]] = j res = max(j-i, res) j += 1 return res
统计结果概率
你选择掷出 num 个色子,请返回所有点数总和的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 num 个骰子所能掷出的点数集合中第 i 小的那个的概率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defstatisticsProbability(self, num: int) -> List[float]: f = [1/6] * 6 if num == 1: return f for i inrange(2,num+1): g = f + [0]*5 for j inrange(5*i+1): #反向推导,有越界问题,需分类讨论 if j < 6: #前段取j个概率和 g[j] = sum(f[:j+1]) * 1/6 elif j < 5*num-4: #中段取6个概率和 g[j] = sum(f[j-5:j+1]) * 1/6 else: #后段取5*i+1-j个概率和 g[j] = sum(f[j-5:]) * 1/6 f = g return f
1 2 3 4 5 6 7 8 9 10 11
#思路相同,但是极大地简化了代码 classSolution: defstatisticsProbability(self, n: int) -> List[float]: dp = [1 / 6] * 6 for i inrange(2, n + 1): tmp = [0] * (5 * i + 1) for j inrange(len(dp)): #正向推导,由旧骰子推到新骰子 for k inrange(6): tmp[j + k] += dp[j] / 6 dp = tmp return dp
模糊搜索验证
请设计一个程序来支持用户在文本编辑器中的模糊搜索功能。用户输入内容中可能使用到如下两种通配符:
‘.’ 匹配任意单个字符。
‘*’ 匹配零个或多个前面的那一个元素。
请返回用户输入内容 input 所有字符是否可以匹配原文字符串 article。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defarticleMatch(self, s: str, p: str) -> bool: s, p = '0'+s, '0'+p #用'0'来代替'',使得题解更清晰 m, n = len(s), len(p) #dp[i][j]表明s[:i+1]是否与p[:j+1]匹配,因为我们前面加上了'0',所以这里dp[i][j]与s[i],p[j]关联 dp = [[False ] * n for _ inrange(m)] dp[0][0] = True for j inrange(2, n, 2): #初始化首行 dp[0][j] = dp[0][j-2] and p[j] == '*'# 'x*'可视为'' for i inrange(1,m): for j inrange(n): if p[j] == '*': if dp[i][j-2] or (dp[i-1][j] and p[j-1] in [s[i],'.']): dp[i][j] = True else: if dp[i-1][j-1] and p[j] in [s[i],'.']: dp[i][j] = True return dp[-1][-1]
#快速排序 classSolution: defcrackPassword(self, password: List[int]) -> str: n= len(password) for i inrange(n): password[i] = str(password[i]) for i inrange(n): stop = True for j inrange(n-i-1): ifint(password[j]+password[j+1]) > int(password[j+1]+password[j]): password[j], password[j+1] = password[j+1], password[j] stop = False if stop: break return''.join(password)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#快速排序 classSolution: defcrackPassword(self, password: List[int]) -> str: n= len(password) for i inrange(n): password[i] = str(password[i]) defquick_sort(l,r): if l >= r: return i, j = l, r while i < j: while i<j andint(password[l]+password[j]) <= int(password[j]+password[l]): j-=1 while i<j andint(password[l]+password[i]) >= int(password[i]+password[l]): i+=1 password[i], password[j] = password[j], password[i] password[l], password[i] = password[i], password[l] quick_sort(l,i-1) quick_sort(i+1,r) quick_sort(0,n-1) return''.join(password)
1 2 3 4 5 6 7 8 9 10 11 12
#定义排序规则,使用sort的key classSolution: defcrackPassword(self, password: List[int]) -> str: defsort_rule(x, y): a, b = x + y, y + x if a > b: return1 elif a < b: return -1 else: return0 strs = [str(num) for num in password] strs.sort(key = functools.cmp_to_key(sort_rule)) return''.join(strs)
#不考虑大数 classSolution: defcuttingBamboo(self, bamboo_len: int) -> int: n = bamboo_len if n < 4: return n-1 x = n // 3 y = n % 3 if y == 0: return3**x elif y == 1: return3**(x-1)*4 else: return3**x*2
1 2 3 4 5 6 7 8 9 10
#考虑大数 classSolution: defcuttingBamboo(self, bamboo_len: int) -> int: n, mod = bamboo_len, 1000000007 if n < 4: return n-1 x = n // 3 y = n % 3 if y == 0: returnpow(3,x,mod) elif y == 1: returnpow(3,x-1,mod)*4 % mod else: returnpow(3,x,mod)*2 % mod
classSolution: defsockCollocation(self, sockets: List[int]) -> List[int]: x, y ,n, m = 0, 0, 0, 1 for num in sockets: n ^= num #求出目标值x^y while m & n == 0: m <<= 1#找出x^y中为1的位(x与y不同的位),通过m记录 for num in sockets: #靠不同位将数组分为两类 if num & m: x ^= num #找出不重复的x else: y ^= num #找出不重复的y return x,y
#摩尔投票法 #抵消掉不同的树,剩下的一定是众数 classSolution: definventoryManagement(self, stock: List[int]) -> int: votes, count = 0, 0 for num in stock: if votes == 0: x = num votes += 1if num == x else -1 # 验证 x 是否为众数 for num in stock: if num == x: count += 1 return x if count > len(stock) // 2else0# 当无众数时返回 0
classSolution: deftwoSum(self, price: List[int], target: int) -> List[int]: i, j = 0, len(price)-1 while i < j: if price[i]+price[j] == target: return [price[i],price[j]] while i<j and price[i]+price[j] > target: j -= 1 while i<j and price[i]+price[j] < target: i += 1
classSolution: defdigitOneInNumber(self, num: int) -> int: n = num digit, res = 1, 0 high, cur, low = n // 10, n % 10, 0#高位,当前位,低位 while high != 0or cur != 0: #高位和当前位同时为0说明溢出 if cur == 0: res += high * digit elif cur == 1: res += high * digit + low + 1 else: res += (high + 1) * digit low += cur * digit cur = high % 10 high //= 10 digit *= 10 return res
找到第 k 位数字
某班级学号记录系统发生错乱,原整数学号序列 [0,1,2,3,4,…] 分隔符丢失后变为 01234… 的字符序列。请实现一个函数返回该字符序列中的第 k 位数字。
1 2 3 4 5 6 7 8 9 10
classSolution: deffindKthNumber(self, k: int) -> int: res, n, nine = 0, 0, 0.9 while res < k: #找出k是在n位数中 nine *= 10 n += 1 res += nine * n x, y = (int(res) - k) // n, (int(res) - k) % n #第n位数最大者中反推k pur = 10**n - 1 - x returnint(str(pur)[-1-y])
#约瑟夫环,x→(x+t) mod n classSolution: deficeBreakingGame(self, num: int, target: int) -> int: x = 0 for i inrange(2, num + 1): x = (x + target) % i return x