
二叉树相关知识点
二叉树的一些概念
二叉树(Binary tree)是树形结构的一个重要类型。许多实际问题抽象出来的数据结构往往是二叉树形式,即使是一般的树也能简单地转换为二叉树,而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。二叉树特点是每个节点最多只能有两棵子树,且有左右之分。
二叉树是n个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树。当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称作一个节点。
把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
1.每个节点有零个或多个子节点;
2.没有父节点的节点称为根节点;
3.每一个非跟节点有且仅有一个父节点;
4.除了根节点以外,每个子节点可以分为多个不想交的子树。
节点的度:节点拥有的子树的数目。
叶子:度为零的节点。
分支节点:度不为零的节点。
树的度:树中节点的最大的度
层次:根节点的层次为1,其余节点的层次等于该节点的双亲节点加1。
树的高度:树中节点的最大层次。
无序数:如果树中节点的各子树之间的次序是不重要的,可以交换位置,有序数:如果树中结点的各子树的次序是重要的,不可以交换位置,
森林:0个或多个不相交的树组成。对森林加上一个根,森林即成为树;删去根,树即成为森林
完全二叉树: 一颗二叉树中,只有最下面两层节点的度可以小于2,并且最下层的叶节点集中在靠左的若干位置上
平衡二叉树:高度差小于1
原文链接:https://blog.csdn.net/qq_41404557/article/details/115447169
二叉树的前序、中序、后序遍历
原文链接:二叉树的前序、中序、后序遍历(个人笔记)
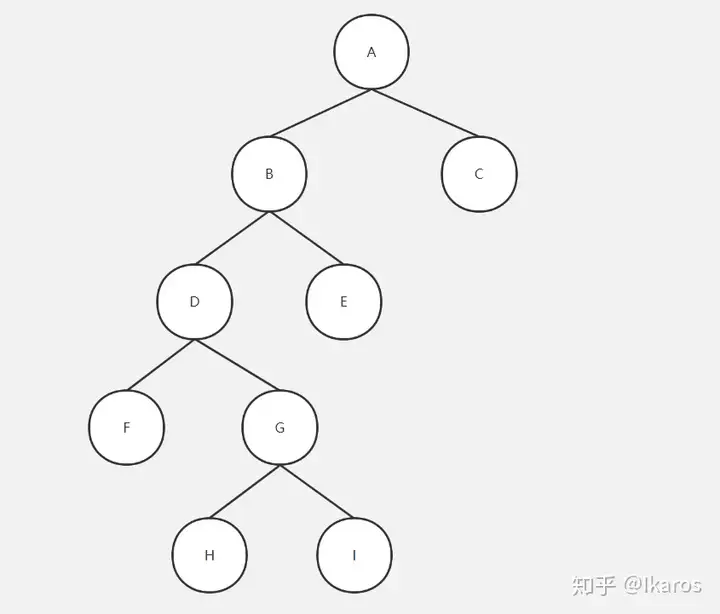
二叉树:

前序遍历A-B-D-F-G-H-I-E-C
中序遍历F-D-H-G-I-B-E-A-C
后序遍历F-H-I-G-D-E-B-C-A
前序(根左右),中序(左根右),后序(左右根)
例题1:
已知某二叉树的前序遍历为A-B-D-F-G-H-I-E-C,中序遍历为F-D-H-G-I-B-E-A-C,请还原这颗二叉树。
解题思路:
从前序遍历中,我们确定了根结点为A,在从中序遍历中得出 F-D-H-G-I-B-E在根结点的左边,C在根结点的右边,那么我们就可以构建我们的二叉树的雏形。
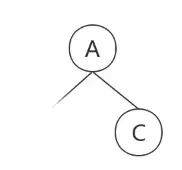
那么剩下的前序遍历为B-D-F-G-H-I-E,中序遍历为F-D-H-G-I-B-E, B就是我们新的“根结点”,从中序遍历中得出F-D-H-G-I在B的左边,E在B的右边,继续构建
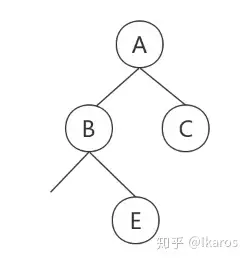
那么剩下的前序遍历为D-F-G-H-I,中序遍历为F-D-H-G-I,D就是我们新的“根结点”,从中序遍历中得出F在D的左边,H-G-I在D的右边,继续构建
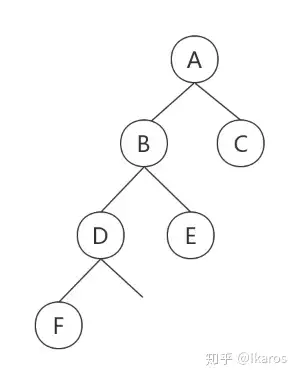
那么剩下的前序遍历为G-H-I,中序遍历为H-G-I,G就是我们新的“根结点”,从中序遍历中得出H在G的左边,I在G的右边,继续构建
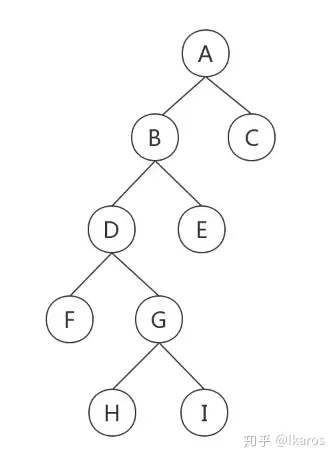
例题2:
已知某二叉树的中序遍历为F-D-H-G-I-B-E-A-C,后序遍历为F-H-I-G-D-E-B-C-A,请还原这颗二叉树。
解题思路:
从后序遍历中,我们确定了根结点为A,在从中序遍历中得出 F-D-H-G-I-B-E 在根结点的左边,C在根结点的右边,那么我们就可以构建我们的二叉树的雏形。之后就是新根节点B,FDHGI在根左,E在根右。在之后就是新根D,F根左,HGI根右,然后就差不多了。
和前序和中序还原二叉树一样,我们同理可以通过中序和后序还原二叉树。
光有前序遍历和后序遍历是无法还原二叉树的。
方法:先找根,再分左右
二叉搜索树
原文链接:数据结构——二叉搜索树详解
一、什么是二叉搜索树
二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树。
二叉搜索树:一棵二叉树,可以为空;如果不为空,满足以下性质:
非空左子树的所有键值小于其根结点的键值。
非空右子树的所有键值大于其根结点的键值。
左、右子树都是二叉搜索树。
下图是几个例子:

上图值为10的结点的右子树为7,比10小,不满足条件2,所以这棵树不是二叉搜索树。

上图各个结点都满足条件,所以这棵树是二叉搜索树。

上图各个结点都满足条件,所以这棵树也是二叉搜索树。
看完上面的介绍后,相信大家都对什么是二叉搜索树有了较为清晰的认识。接下来说一下二叉搜索树的一些基本操作。
二、二叉搜索树的基本操作
二叉树的结构
1 | typedef int ElementType; |
1. 二叉搜索树的查找操作:
(1)查找从根结点开始,如果树为空,返回NULL
(2)若搜索树非空,则根结点关键字和X进行比较,并进行不同处理:
① 若X小于根结点键值,只需在左子树中继续搜索;
② 如果X大于根结点的键值,在右子树中进行继续搜索;
③若两者比较结果是相等,搜索完成,返回指向此结点的指针。
下图为在这棵树中寻找X的示意图:如果X大于r,就继续去TR找;如果X小于r,就去TL找,如果相等,那么查找成功,直接返回。

代码如下:
1 | Position Find( ElementType X, BinTree BST ) |
值得说明的是,上述的代码使用的是递归的方式,而使用递归会导致效率不高。恰巧这段代码又是尾递归的方式(尾递归就是程序分支的最后,也就是最后要返回的时候才出现递归),从编译的角度来讲,尾递归都可以用循环的方式去实现。由于非递归函数的执行效率高,可将“尾递归”函数改为迭代函数。
代码如下:
1 | Position IterFind( ElementType X, BinTree BST ) |
最后要说的是,查找的效率决定于树的高度。
2.查找最大和最小元素
首先说明的是:
①最大元素一定是在树的最右分枝的端结点上。
②最小元素一定是在树的最左分枝的端结点上。

根据上述两点,我们可以很轻松的把代码写出来:
1 | Position FindMin( BinTree BST ) |
上面是查找最小元素的递归函数,由于这也是个尾递归,所以我们依旧可以把它改成迭代函数,在这里我就不重复写了,直接写查找最大元素的迭代函数。代码如下:
1 | Position FindMax( BinTree BST ) |
3.二叉搜索树的插入
二叉搜索树在插入前,肯定要找到插入的位置。所以解决这个问题的关键就是要找到元素应该插入的位置,可以采用与Find类似的方法。下图演示了在二叉搜索树中插入35的过程。

代码如下:
1 | BinTree Insert( BinTree BST, ElementType X ) |
举个例子:以一年十二个月的英文缩写为键值,按从一月到十二月顺序输入,即输入序列为(Jan, Feb, Mar, Apr, May, Jun, July, Aug, Sep,Oct, Nov, Dec)。想一想结果是怎么样的呢?如下图所示:(站长注:为字母的ASCII码顺序排列)

4.二叉搜索树的删除
对于二叉搜索树的删除,相对来说就比较麻烦了。因为要考虑以下三种情况:
①要删除的是叶结点;
②要删除的结点只有一个孩子结点;
③要删除的结点有左、右两棵子树;
对于上述的三种情况,我们要怎么做呢?
情况①:
叶结点就是左右子树都为空的结点,既然左右子树都为空,删掉它并没什么后顾之忧,所以当我们要删除的是叶结点的时候,直接删除就好了。当然不要忘记一个重要的操作——删除之后要修改其父结点指针,即置为NULL。
举个例子方便理解:如下图所示:
情况②:
当要删除的结点只有一个孩子结点,我们删除该结点后需要考虑怎么处置它的孩子结点。因为被删除的结点的孩子无论是左孩子还是右孩子,都只会比被删除的结点的父结点小,所以我们只需要将被删除的结点的父结点的指针指向被删除的结点的孩子结点。
举个例子方便理解:如下图所示:

情况③:
当删除的结点有左、右两棵子树,我们删除该结点后需要考虑怎么处置它的孩子结点。此时最简单的办法就是用另一结点替代被删除结点,那我们要用哪一个结点呢?根据二叉搜索树的定义:每一个结点的右孩子都比自己大,左孩子都比自己小。要取哪一个结点替代被删除的结点同时又保证该特性呢?所以根据此情况,我们很快就能判断出用被删除结点的右子树的最小元素或者左子树的最大元素替代被删除结点。
举个例子方便理解:如下图所示:


值得注意的是:当我们找到元素替代被删除的结点后,我们也要删除用来替代元素。删除该元素的方法也是按照以上3种情况分析
上述三种情况分析完之后,就要用代码把他们表示出来了,代码如下:
1 | BinTree Delete( BinTree BST, ElementType X ) |